Base de Datos en Memoria

Base de Datos en Memoria
Las bases de datos se han convertido en una herramienta poderosa en el desarrollo de la ingeniería del software, ya no podemos imaginar aplicativos sin tener base de datos. Almacenar información en base de datos, validarla y consumirla es importante, pero buscar la optimización del uso de base de datos se ha vuelto imperativo en estos últimos tiempos.
Pero así como la base de datos es de vital importancia, la evolución en el uso de la información ha dado como resultado la evolución también de la base de datos tradicionales conllevando a nuevas formas de almacenar y explotar la información. Todo ello debido al crecimiento vertiginoso de la base de datos, debido a que ahora se genera más información que proviene de dispositivos móviles, internet, dispositivos electrónicos, etc.
Así podemos mencionar las siguientes alternativas en base de datos:
- Base de Datos Relacionales
- Base de Datos Analíticas Multidimensionales
- Base de Datos Analíticas On Memory
- Base de Datos Predictivas
- Base de Datos Jerárquicas
- Base de Datos Orientada a Objetos
- Base de Datos On Cloud
- Base de Datos No Relacionales (NoSQL)
En el mercado podemos encontrar las siguientes alternativas de base de datos analíticos on Memory:
- SQL Server Analysis Services Tabular (Base de datos en memoria de la empresa Microsoft)
- IBM dashDB (Base de datos en memoria de la empresa IBM)
- IBM Informix Warehouse Accelerator (Base de datos en memoria de la empresa IBM)
- SAP Hana (Base de datos en memoria de la empresa SAP)
- WebDNA (Base de datos en memoria de la empresa WebDNA Corporation)
- AeroSpike (Base de datos en memoria de la empresa AeroSpike Company)
- Altibase (Base de datos en memoria de la empresa Altibase Corporation)
- Apache Geode (Base de datos en memoria de la empresa Apache Software Foundation)
- BigMemory (Base de datos en memoria de la empresa Terracotta Inc.)
- DB2 BLU (Base de datos en memoria de la empresa IBM)
- Ehcache (Base de datos en memoria de la empresa Terracotta Inc.)
- EXASolution (Base de datos en memoria de la empresa EXASOL)
- InMemory.Net (Base de datos en memoria de la empresa InMemory.Net)
- Kognitio Analytical Platform (Base de datos en memoria de la empresa Kognitio Limited)
- SQLite (Base de datos en memoria de la empresa SQLite)
- MonetDB (Base de datos en memoria de la empresa CWI)
- Oracle 12c (Base de datos en memoria de la empresa Oracle)
- Polyhedra (Base de datos en memoria de la empresa ENEA AB)
- SafePeak (Base de datos en memoria de la empresa SafePeak Tech)
- Tarantool (Base de datos en memoria open source)
- TimesTen (Base de datos en memoria de la empresa Oracle)
- Scuba (Base de datos en memoria de la empresa Facebook)
- VoltDB (Base de datos en memoria de la empresa VoltDB inc)
- Hazelcast (Base de datos en memoria de la empresa Hazelcast Team)
- SolidDB (Base de datos en memoria de la empresa Unicom Global)
Adicionalmente también en el mundo open source podemos encontrar técnicas de manejo de base de datos en memoria como mem-cache, etc.
Empresas tan conocidas como Facebook, Google, Yahoo, Amazon, etc. se han visto en la necesidad de utilizar base de datos en memoria para acelerar sus búsquedas y transacciones así como mejorar la experiencia de usuario.
Técnicas:
Una base de datos en memoria también conocida como base de datos en memoria principal, almacena sus datos en memoria para facilitar tiempos más rápidos de respuesta. La base de datos en memoria carga la data en un formato comprimido no relacional. Adicionalmente la base de datos en memoria optimiza el trabajo relacionado con el procesamiento de las consultas.
Este tipo de base de datos además de brindar tiempos extremadamente rápidos de respuesta a consultas, reduce la necesidad de indexar datos en base de datos en memoria.
Adicionalmente la computación de 64 bits, servidores multi-nucleo y los bajos costos de memoria han hecho posible la aplicación de estas técnicas en base de datos en memoria.
Diseño de almacenamiento de base de datos en memoria:
La construcción del diseño del almacenamiento de base de datos en memoria, no puede dejar de lado la estructura en niveles (jerarquía) de la memoria del computador, sobre el cual se ejecutarán y almacenarán las consultas de la base de datos en memoria. Así tenemos los siguientes niveles de memoria en la base de datos:
a.- Nivel Caché 1, llamado L1, incluido en el interior del chip del procesador.
b.- Nivel Caché 2, llamado L2, se encuentra fuera del procesador, pero en la placa madre.
c.- La memoria principal.
Optimización de Rendimiento en Memoria Principal para base de datos en memoria
Para el uso eficiente de la base de datos en memoria se debe habilitar el modo Quad Channel, que es la configuración más rápida en base de datos en memoria y consiste en llenar el primer banco de memoria (más próximo al procesador) que consta de 4 slot y llenar los 4 slots. Con el ello el uso intensivo de la base de datos en memoria se ve maximizado versus el uso del single cannel.
Usos:
Como base de datos OLTP:
La base de datos en memoria OLTP almacena los datos a nivel de filas y se utilizan para almacenar y procesar datos transaccionales.
Como base de datos OLAP:
La base de datos en memoria OLAP es una base de datos analítica, que es a su vez un sistema de sólo lectura con datos históricos para la generación de indicadores en aplicaciones de inteligencia de negocios y el almacenamiento de esta base de datos es típicamente en columna.
Ventajas:
Las ventajas de trabajar con base de datos en memoria son:
- Su principal soporte de almacenamiento es la memoria.
- No consume CPU
- Es más veloz que el almacenamiento en disco.
Velocidad: la base de datos en memoria al almacenar toda su data en memoria RAM su velocidad de acceso es de 80milisegundo en promedio, mientras que la velocidad de acceso a disco duro es de 5 milisegundos, el cual es utilizado por base de datos tradicionales, es una diferencia de casi 100,000 veces. Y si estos tiempos los comparamos con almacenamiento en base de datos basado en discos de estado sólido o memoria FLASH no-volátil se estima en 1000 veces más lento que usando memoria RAM para esta base de datos.
Persistencia: La duda en general para base de datos en memoria es que sucede en caso de pérdida de fuente de energía, para ello la base de datos en memoria permiten que las páginas de memoria RAM se escriben en almacenamiento no-volátil. Además la base de datos en memoria no considera completa la transacción completada hasta que esta no se grabe en el log de transacciones, ello también permite que en caso de falla se pueda recuperar la página más reciente de la base de datos en memoria y vuelva a aplicarse las operaciones desde el log.
Microsoft SQL Server Analysis Services Tabular
Esta herramienta de Microsoft utiliza el motor de almacenamiento de base de datos en memoria xvelocity, que utiliza dos técnicas:
- Algoritmos de compresión de Datos
- Procesamiento multihilos
Analysis Services Tabular accede a los datos de dos modos:
- Modo Caché:
- Modo Direct Query:
Modo Caché:
Permite acceder a múltiples fuentes de datos, tales como: base de datos relacionales, archivos de texto, etc. y colocarlos directamente en la memoria del a base de datos.
Modo Direct Query:
Permite realizar un by pass de la configuración de la base de datos en memoria para acceder directamente al disco.
Comprobando el Servicio Microsoft SQL Server Analysis Services Tabular:
Antes de desarrollar un proyecto de base de datos analíticas en memoria debemos comprobar que el servicio se encuentre instalado y corriendo en el servidor, para ello usamos la herramienta Microsoft SQL Server Configuration Manager:
Creando un proyecto Microsoft SQL Server Analysis Services Tabular:
1.- Utilizaremos la herramienta SQL Server Data Tools que es una versión reducida de visual studio (versión Shell), el cual nos permitirá crear la base de datos analítica en memoria:
2.- Nos posicionamos en el menú File, New, Project y escogemos el template Analysis Services Tabular Project y le colocamos el nombre OnMemoryTabularDemo:
 3.- Luego se requiere indicar el servidor de espacio temporal (workspace), este servidor permite actuar como un área de trabajo (staging área) para la base de datos en memoria, previo a la publicación en el servidor analítico:
3.- Luego se requiere indicar el servidor de espacio temporal (workspace), este servidor permite actuar como un área de trabajo (staging área) para la base de datos en memoria, previo a la publicación en el servidor analítico:
4.- Luego requerimos de un origen de datos que formarán parte de nuestra base de datos en memoria, para ello usaremos la base de datos AdventureWorkdDW que puede ser descargada del siguiente en lace: http://msftdbprodsamples.codeplex.com/releases/view/59211
5.- En el menú Model / Import From data source, escogemos como motor de base de datos Microsoft SQL Server:
6.- Luego seleccionamos el servidor y la base de datos:
7.- Luego seleccionamos las tablas que deseamos formen parte de la base de datos en memoria:
8.- Luego podemos limitar las columnas de cada entidad, para no subir a la base de datos en memoria campos innecesarios, seleccionamos la tabla DimCustomer y le damos clic al botón Preview & Filter:
9.- De la tabla DimCustomer quitamos las siguientes columnas: Title, MiddleName,NameStyle, Suffix, SpanishEducation, FrenchEducation, SpanishOcupation,FrenchOcupation.
10.- De igual manera filtramos la tabla DimDate quitando las siguientes columnas: SpanishDayNameOfWeek, FrenchDayNameOfWeek, SpanishMonthName, FrenchMonthName, CalendarSemester, FiscalSemester y le damos clic en el botón Finish.
11.- Luego la información será cargada en la base de datos en memoria:
12.- Luego se mostrará la información ya cargada en nuestra base de datos en memoria.
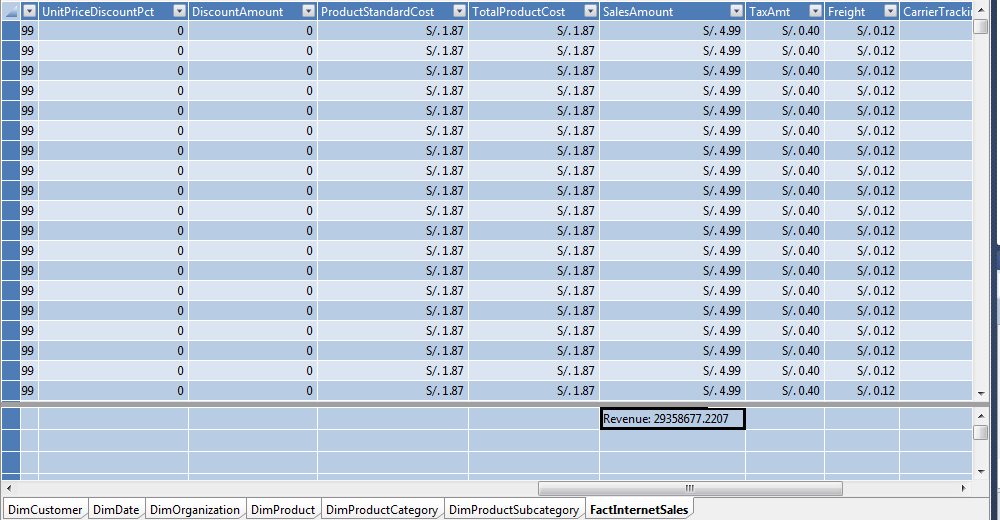
13.- La base de datos tabulares en memoria necesita de un objeto llamado “Medida”. Estas medidas son sencillas de crear, muy similar a fórmulas Excel.
14.- Creamos la medida Revenue (Ingresos), para ello nos posicionamos en la tabla FactInternet Sales y debajo de la columna SalesAmount, digitamos la siguiente fórmula:
Revenue:=SUM([SalesAmount])
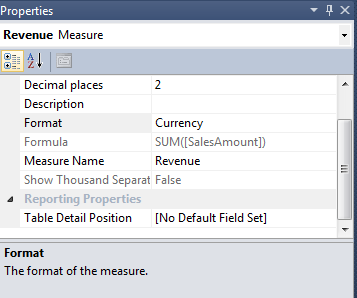
15.- La medida debe tener el mismo tipo de dato que sus columnas orígenes, por lo que se procederá a cambiarle de formato, usando la propiedad Format, la cambiaremos a Currency:
 16.- Creamos una segunda medida llamada Cost, con formato Currency:
16.- Creamos una segunda medida llamada Cost, con formato Currency:
Cost:=Sum([TotalProductCost])
Analizando datos en base de datos en memoria:
17.- En el menú Model, elegimos la opción Analyze in Excel:
18.- Usamos la opción Current Windows User:
19.- En la tabla dinámica de Excel elegimos la medida Revenue:
20.- Luego escogemos de la tabla dinámica de la tabla DimDate, el atributo Calendar Year, para ver los ingresos por año:
21.- Sin embargo no sabemos si este año corresponde a la fecha de la orden (Order date), fecha de envío (Ship date) o la fecha estimada (due date).
22.- Añadimos ahora el nombre del mes y notamos que el nombre está ordenado en forma alfabética:
Relaciones en Base de Datos en Memoria
Cuando importamos datos de una base de datos relacional podemos elegir que se mantengan automáticamente las relaciones que tienen en el origen. Sin embargo los analistas de base de datos frecuentemente requerirán analizar datos de diferentes fuentes y para el cual las relaciones explícitas no existen. En este caso podemos definir manualmente las relaciones en la base de datos en memoria.
Cuando creemos relaciones entre dos tablas de nuestra base de datos en memoria, ambas deben contener un campo en común. Si una tabla contiene múltiples relaciones sólo una se encuentra activa y se muestra como una línea gruesa y las no activas como líneas punteadas. Si deseamos convertir las relaciones de la base de datos en memoria inactivas en activas, debemos copiar la tabla con diferente nombre y crear relaciones activas.
Tipos de datos en columnas
En el proceso de importación de datos al modelo da la base de datos en memoria, se puede especificar el tipo de datos de las columnas, por ejemplo si un campo ese la fecha de nacimiento, podemos indicar que es del tipo fecha.
Columnas Calculadas
En la base de datos en memoria también se pueden crear columnas calculadas, por ejemplo si tenemos la tabla de clientes con los campos nombres y apellidos, podemos crear un campo que concatene ambos campos formando el campo: Nombre Completo.
Ordenamiento de Columnas
Igualmente en la base de datos en memoria podemos realizar un ordenamiento de columnas basados en otras columnas, por ejemplo si tenemos la columna nombre del mes, podemos ordenarla por número del mes.
Ocultando columnas en el cliente
Otra característica que podemos implementar en la base de datos en memoria es ocultar campos innecesarios para el usuario final.
23.- Ingresamos al modo de diagrama de la base de datos en memoria, vamos al menú Model, Model View, Diagram View:
24.- Le damos doble clic a la relación que tiene la línea gruesa y comprobamos que el campo OrderDateKey es la relación Activa:
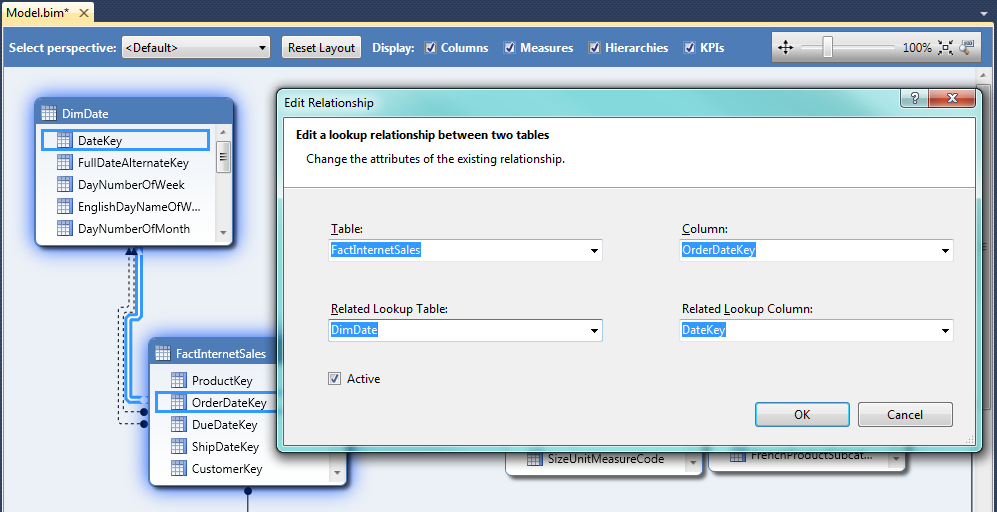 25.- A continuación procedemos a borrar las relaciones inactivas (líneas punteadas) y cambiamos el nombre de tabla a Order Date:
25.- A continuación procedemos a borrar las relaciones inactivas (líneas punteadas) y cambiamos el nombre de tabla a Order Date:
26.- Agregamos una tabla adicional de tiempo para crear otra relación activa, para ello vamos al menú Model, Existing Connection:
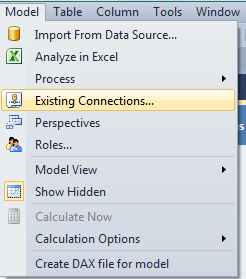 27.- Luego abrimos la cadena de conexión de la base de datos, en la opción Open:
27.- Luego abrimos la cadena de conexión de la base de datos, en la opción Open:
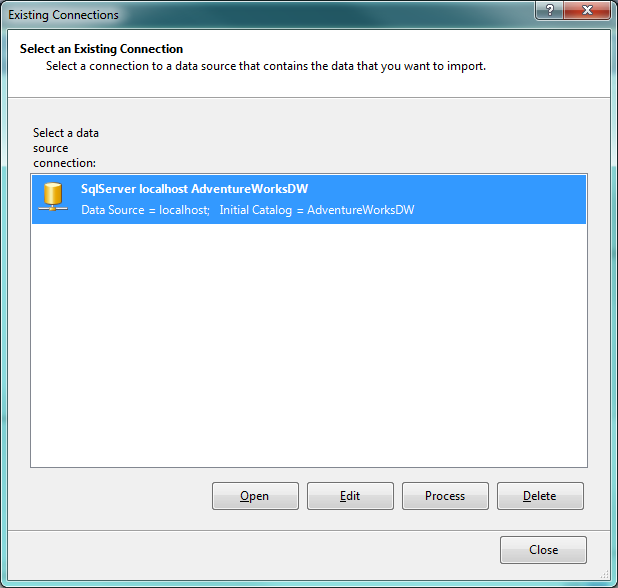 28.- Seleccionamos la tabla DimDate y le colocamos el friendly name ShipDate:
28.- Seleccionamos la tabla DimDate y le colocamos el friendly name ShipDate:
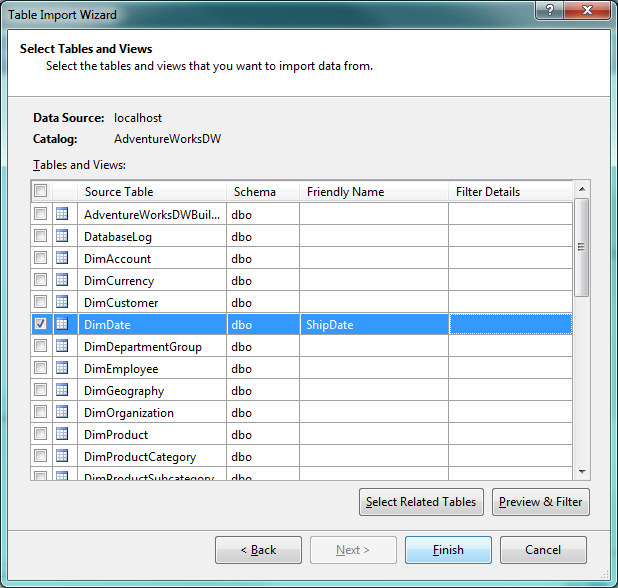 29.- Luego le damos clic en el botón Preview & Filter y deseleccionamos los campos: SpanishDayNameOfWeek, FrenchDayNameOfWeek, SpanishMonthName, FrenchMonthName, CalendarSemester, FiscalSemester:
29.- Luego le damos clic en el botón Preview & Filter y deseleccionamos los campos: SpanishDayNameOfWeek, FrenchDayNameOfWeek, SpanishMonthName, FrenchMonthName, CalendarSemester, FiscalSemester:
30.- Luego creamos la relación, arrastramos de la tabla FactInternetSales el campo ShipDateKey sobre el campo DateKey de la tabla ShipDate:
31.- Maximizamos la tabla OrderDate y con la tecla Ctrl seleccionamos los campos DateKey, DatNumberOfWeek y MonthNumberOfYear, clic derecho y la opción Hide from Client Tools, esto para que estos campos queden ocultos en la herramienta del cliente:
32.- A continuación renombramos las siguientes columnas: FullDateAlternateKey a Date, EnglishDayNameOfWeek a Weekday y el campo EnglishMonthName a Month:
33.- Maximizamos la tabla Internet Sales y solo dejamos visible cost y revenue:
34.- A continuación veremos como ordenar un campo por otro campo, para ello regresamos a la vista de datos, Mode / Model view / Dagraman :
35.- Nos colocamos en la columna Weekday y del menú Column, escogemos, Sort y Sort by Column:
36.- En el cuadro de dialogo Sort by Column escogemos en By Column, DayNumberOfWeek:
37.- Ordenamos de igual manera el campo Month usando el campo MonthNumberOfYear:
38.- Realizamos nuevamente el análisis de la base de datos en memoria usando Excel, observamos que la tabla Internet Sales ya no aparece más y los meses se muestran ahora ordenados:
Jerarquías
Una jerarquía es una colección de atributos organizados en niveles. Es usado para facilitar al usuario la experiencia de navegar por la información en la base de datos en memoria.
39.- Ingresamos en modo Diagrama, menú Model, Model View, Diagram View:
40.- Maximizamos la tabla OrderDate y le damos clic en el ícono Create Hierarchy:
41.- Colocamos el nombre de la jerarquía (Calendar Date):
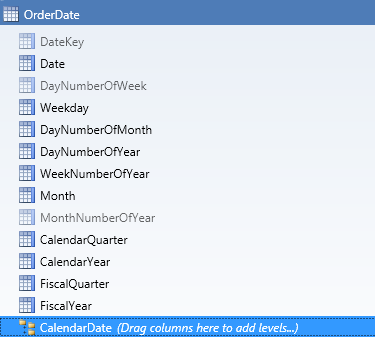 42.- Creamos los siguientes niveles en la jerarquía CalendarDate:
42.- Creamos los siguientes niveles en la jerarquía CalendarDate:
- CalendarYear
- CalendarQuarter
- Month
- Date
43.- Visualizamos en Excel la creación de la jerarquía (CalendarDate) realizando un reporte por ingresos (Revenue):
44.- La jerarquía CalendarDate nos permite realizar la operación OLAP drill down (desplegar hacia abajo) y drill up (desplegar hacia arriba):
Despliegue de Base de Datos On Memory
Una vez que hemos generado nuestra base de datos en memoria dentro de nuestra herramienta cliente SQL Server Data Tools, debemos hacer el despliegue en el servidor. Para ello debemos indicar cuál es el servidor que almacenará la base de datos en memoria.
45.- Ingresamos a propiedades del proyecto OnMemoryTabularDemo:
46.- Colocamos el nombre del servidor de base de datos en memoria en la opción Server, colocamos el nombre de la base de datos como DemoDB y el nombre del cubo le colocamos InternetSales.
47.- Para desplegarlo en el servidor de base de datos vamos al menú Build, Deploy OnMemoryTabularDemo:
48.- Comprobamos que el despliegue en la base de datos en memoria ha sido éxitoso con el mensaje Success y le damos clic en el botón Close:
49.- Verificamos el despliegue en el servidor de base de datos en memoria, ingresando a través de Excel. En el menú Data, From Other Sources, From Analysis Services:
50.- Luego colocamos el nombre el servidor de base de datos en memoria:
51.- Comprobamos que la base de datos es DemoDB y el cubo Internet Sales:
52.- Luego escogemos la opción Pivot Table Report:
53.- En el Excel seleccionamos la medida Revenue, luego la jerarquía CalendarDate y en la zona de columnas colocamos el atributo de la dimensión Geography, EnglishCountryRegionName:
Columnas Calculadas:
Una columna calculada de una base de datos en memoria, es una nueva columna que puede estar formada por otra columna, operaciones o constantes. Puede referenciar a columnas de la misma tabla o de otras tablas. Generalmente para la creación de columnas calculadas de base de datos en memoria hacemos uso del lenguaje DAX que es muy similar a la sintaxis de las fórmulas en Excel. Por ejemplo, si deseamos hallar la columna calculada SalesProfit, esta se puede calcular con la siguiente fórmula DAX:
SalesProfit:=[Sales Amount]-[Total Product Cost]
Las columnas calculadas se crean en la vista de datos (Data View), en la última columna de la tabla seleccionada. El motor xvelocity de trabajo en memoria se encargará de realizar el cálculo fila por fila, a todas la filas (no se puede hacer a un rango).
54.- Nos posicionamos en la tabla DimCustomer:
55.- Creamos la columna calculada al final de la tabla, dándole doble clic al campo AddColumn y le cambiamos de nombre por FullName:
56.- Con la columna seleccionada Full Name, colocamos en la barra de fórmulas, la siguiente fórmula, que concatena el nombre con el apellido:
=CONCATENATE([FirstName], " " & [LastName])
57.- Luego le damos enter y empezará a realizar el cálculo:
58.- Para que los usuarios no utilicen los campos nombre y apellido en forma independiente los podemos ocultar, para ello seleccionamos la columna FirstName y LastName, clic derecho, Hide from Client Tools:
59.- Creamos otra columna calculada de la base de datos en memoria, para ello nos posicionamos en la tabla FactInternetSales y en la última columna agregamos la columna SalesProfit con la siguiente fórmula:
=[SalesAmount]-[TotalProductCost]
Medidas:
Una medida de base de datos en memoria, es una fórmula nombrada que es utilizada para operaciones de agregación. Las medidas se generan en la vista de datos.
60.- En la tabla FactInternetSales nos posicionamos en la primera celda vacía debajo de la columna SalesProfit e ingresamos la siguiente fórmula:
Profit:=SUM([SalesProfit])
61.- Esta medida de base de datos en memoria se muestra en formato numérico, para cambiarlo a formato de moneda en la ventana de propiedades de la medida, propiedad Format, escogemos currency:
62.- Generemos otra métrica, el cual se llamará Margin y tendrá la siguiente formula y el formato de porcentaje:
KPI
Los KPI (Key Performance Indicator) son usados para hacer comparaciones de medidas en base de datos en memoria, entre un valor actual y un valor objetivo, para medir el desempeño de un negocio. En la base de datos en memoria los KPIs tienen tres elementos:
- Valor Base.- que corresponde al valor actual de la medida.
- Valor Objetivo.- es el valor a alcanzar por la medida actual.
- Umbral de estado.- es un indicador de color sobre un porcentaje del valor actual y el valor objetivo.
63.- En la tabla FactInternetSales le hacemos clic en la celda debajo de la medida Margin y escribimos la siguiente fórmula que correspondería al objetivo del margen de ventas, con formato de porcentaje:
Target Margin:=(SUM('DimProduct'[ListPrice]) - SUM('DimProduct'[StandardCost])) / SUM('DimProduct'[ListPrice])
64.- Para crear el KPI le damos clic derecho a la medida Margin y seleccionamos la opción Create KPI:
65.- Notamos que se abre la ventana de creación de KPIs y comprobamos que la opción KPI base measure (value) es Margin. En la sección Define target value / Measure, seleccionamos Target Margin:
66.- Cambiamos el primer umbral del indicador a 65% y el segundo 90%:
67.- Luego verificamos que la medida Margin posea el icono del KPI:
68.- Procedemos a analizar la columna calculada, medida y kpi en Excel de la base de datos en memoria, para ello nos posicionamos en el menú Model, Analyze in Excel:
69.- En Excel seleccionamos las medidas Profit y Margin, de la tabla DimCustomer seleccionamos el campo calculado FullName, y del KPI seleccionamos Margin, Status, mostrándonos el siguiente reporte de base de datos:
Conclusión:
Hemos visto la facilidad que nos da la base de datos en memoria para la creación de modelos analíticos, proporcionando bases de datos rápidas, flexibles y robustas. Adicionalmente esta base de datos contiene características extendidas como son KPI, columnas calculadas y medidas, permitiendo al usuario una experiencia de reportes más ventajosa y cómoda de usar.
El acceso tradicional de base de datos con acceso a disco irá progresivamente reemplazándose con acceso a estructuras en memoria o disco duros con tecnología memory flash.
Recordar también que técnicamente los acceso de base de datos en disco se miden en milisegundos, mientras que la base de datos en memoria los tiempo de acceso se miden en nanosegundos, siendo definitivamente el factor tiempo determinante cuando se acceden a grandes volúmenes de datos.
Si bien es cierto esta tecnología ha sido implementada a nivel de servidor de base de datos en memoria Microsoft SQL Server Analysis Services, también la tenemos disponibles para los usuarios en forma local como un autoservicio de Business Intelligence a través de un add-in en la hoja de cálculo Excel llamado Power Pivot. Power Pivot también emula una base de datos en memoria pero usando los recursos de la pc del usuario con la mayoría de características de servidor, pudiendo procesar millones de datos en nanosegundos usando los mismos algoritmos y tecnología de SQL Server Analysis Services.
Con respecto a costos de implementación de base de datos en memoria, los recursos de hardware se han abaratado enormemente últimamente por lo que implementar este tipo de base de datos con una amplia cantidad de memoria ya sea como servidor o cliente, es factible. Y si a ello asociamos una solución basado en cloud computing los costos de base de datos en memoria se abaratan muchísimo más, debido a que en cloud los costos son basados en el uso.

Esta obra está bajo una Licencia Creative Commons Atribución-CompartirIgual 3.0 Unported.